Using vCenter Content Library with vRealize Automation 8
To speed up vRA VM deployments a common used practice is to copy the “golden” VM templates to each vSphere cluster with a script or via vRealize Orchestrator. In addition for vRA7 environments, the custom property “CloneFrom” [Custom Property] in combination with an Orchestrator Workflow is used to select the template from the cluster that the new VM is deployed to. All of this is quite a time consuming and error prone job. For vRA8 I decided to research a different approach by making use of the vCenter Content Library.
In reality there are many ways to configure your vCenter(s) and clusters, but in this blogpost I want to look at the scenarios where you have one vCenter and multiple datacenters or multiple clusters within a datacenter. Each datacenter has one or more clusters. See the pictures below for my test setup:
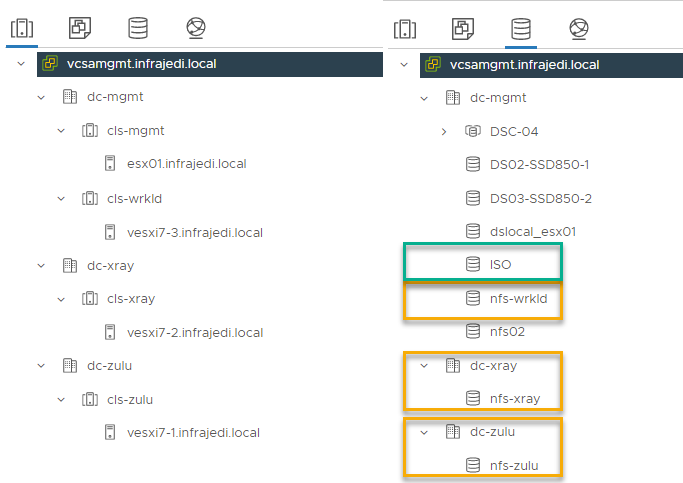
- vCenter 7.0u3c with 3 datacenters.
- Datacenter “dc-mgmt” has two clusters, each with one host
- Datacenters “dc-xray” and “dc-zulu” each have one one cluster with one host.
- Each cluster has its own dedicated NFS datastore.
The version of vRealize Automation I am using is vRA 8.6.2
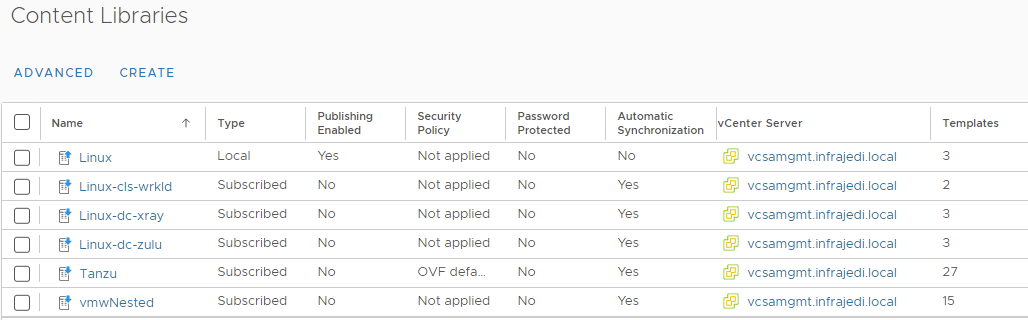
vCenter – Content Libraries
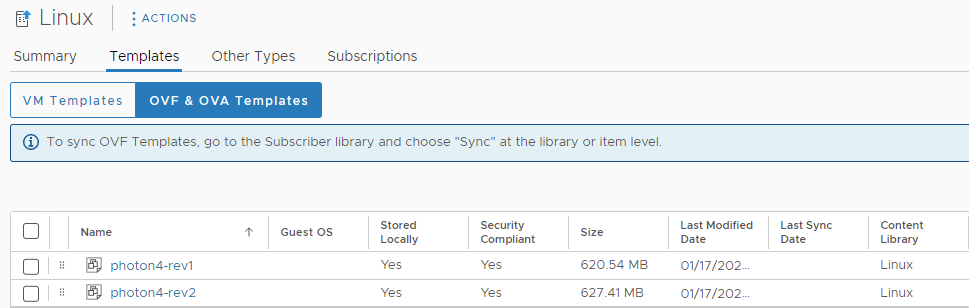
I have created a local content library named “Linux” in the cls-mgmt cluster on the datastore “ISO”.
In this Content Library I have 1 VM Template; “tpl_ubuntu18”.
Note: VM Templates can only be subscribed to if it is in ELM or in the same vCenter
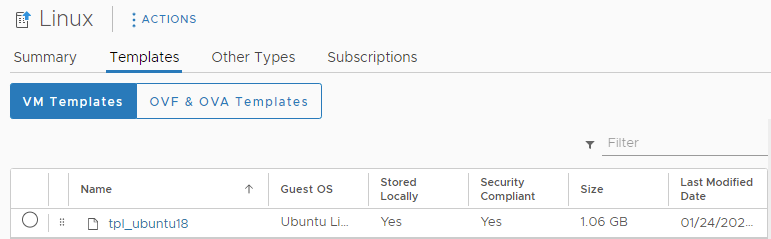
… and 2 OVA Templates; “Photon4-rev1” and “Photon4-rev2”.
-> Btw: Photon is great for deployment testing as it does not require many resources and is very fast to deploy. You can find the Photon OVA files on [Github]. These OVA files can be imported directly in your Content library. Basic GuestOS configuration can be done with cloud-init through a cloudConfig section in your Cloud Templates. See a sample on my [github].
I have created subscriber Content Libraries for each cluster pointing to the local “Linux” Content Library. The Content Libraries are stored on the per cluster dedicated NFS share.
vRA Configuration
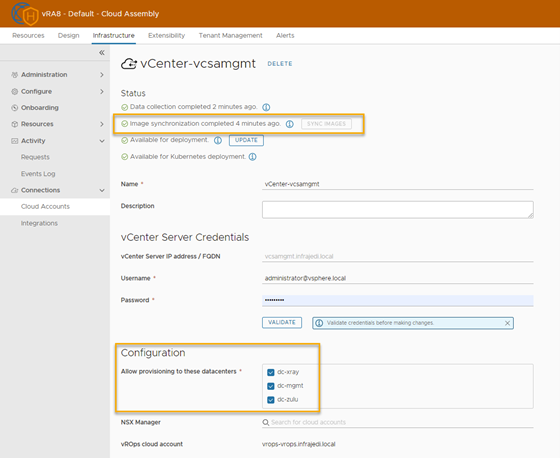
vRA Cloud Account with 3 datacenters:
In my case I added the (virtual) datacenters after vRA Deployment, so I had to change this on the vCenter Cloud Account.
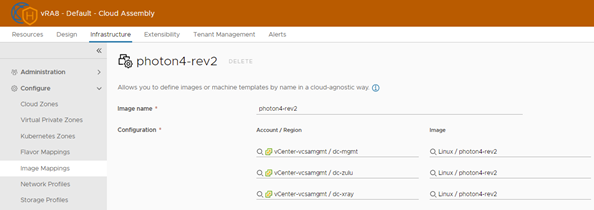
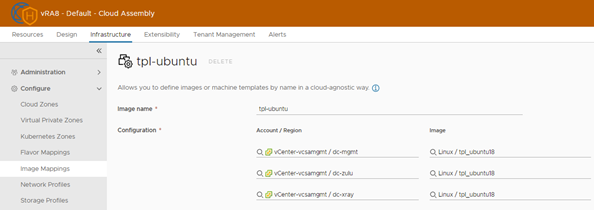
vRA image Mapping
For each image, I have created an image mapping, pointing to the corresponding datacenter. As you may notice from the screenshot, you can only select the Image name of the Local Content Library. This may look a bit confusing, but see the explanation at the end of the blogpost.
To clarify further; it is possible to select an image from a subscribed Content Library
Note: in these tests, I am using “image” in my Cloud Templates. You may also skip the image mapping part and use “imageRef” in your Cloud Templates. See further down below.
vRA Flavor mappings
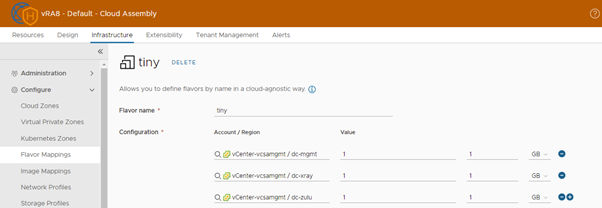
Note: in these tests, I am using “flavor mappings” in my Cloud Templates. You can skip the flavor mapping configuration and use the properties “cpuCount” and “totalMemoryMB” your Cloud Templates if this is for vSphere only. See further down below.
Network Profiles
I have created Network Profiles (just standard switches) for each datacenter and tagged them accordingly. This is not specifically needed for the tested scenario’s, but more part of how my homelab is setup.
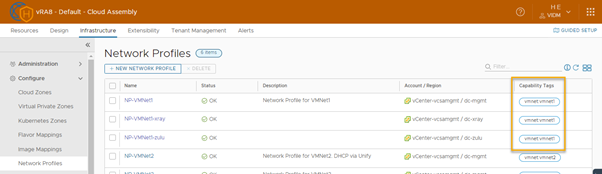
Note: don’t forget to attach a network (Portgroup) form the corresponding Datacenter.
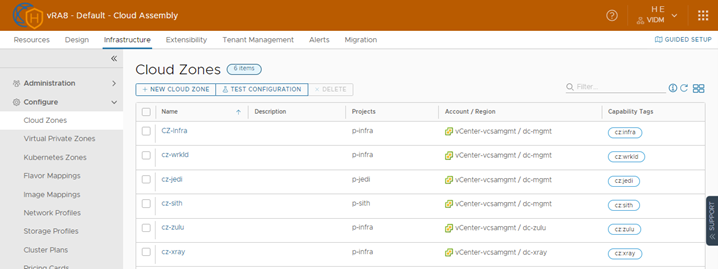
vRA Cloud Zones
I have configured Cloud Zones for each cluster and tagged them with cz:<cluster hostname>
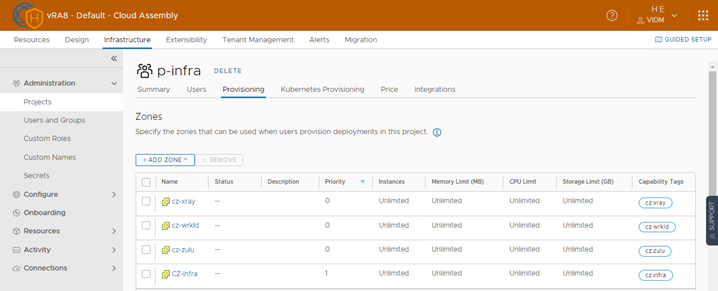
vRA Project
For the project “p-infra” I have added the 4 created Cloud Zones as provisioning Option
vRA Cloud Template
The Cloud Template I have used can be found on [Github].
Note the line “image: photon4-rev2“.
If you don’t want to use image mappings, imageRef can be used: #imageRef: Linux / photon4-rev2
In a similar way if you don’t want to use Flavor Mappings, you can use the “cpuCount” and “totalMemoryMB” properties.
inputs:
vmcloudzone:
type: string
title: Cloud Zone
default: wrkld
enum:
- infra
- xray
- zulu
- wrkld
vmflavor:
type: string
title: Size
default: tiny
enum:
- tiny
- small
- medium
… …
resources:
VM:
type: Cloud.vSphere.Machine
properties:
name: '${propgroup.pgGuestOS.linux + input.pgDeploy.vmEnvironment + input.pgDeploy.vmServertype + input.pgDeploy.vmLocationcode}'
image: photon4-rev2
#imageRef: Linux / photon4-rev2
flavor: '${input.vmflavor}'
#cpuCount: 1
#totalMemoryMB: 1
constraints:
- tag: 'cz:${input.vmcloudzone}'Deployments
Deployment in same datacenter on cluster “cls-wrkld”
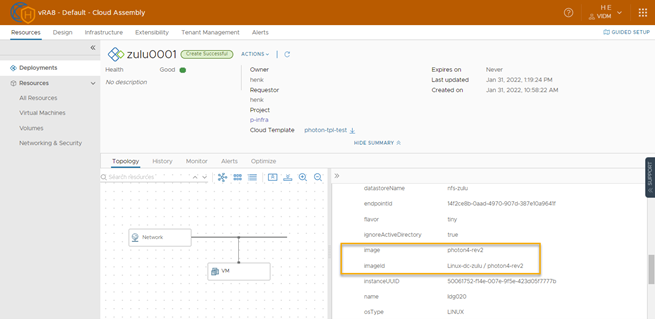
After successful deployment, Select the VM, the Topolgy tab and under Custom Properties look for Image and imageId. As you can see the value for imageId is “Linux-cls-wrkld/photon4-rev2” which relates to the Content Library on the cls-wrkld datastore.
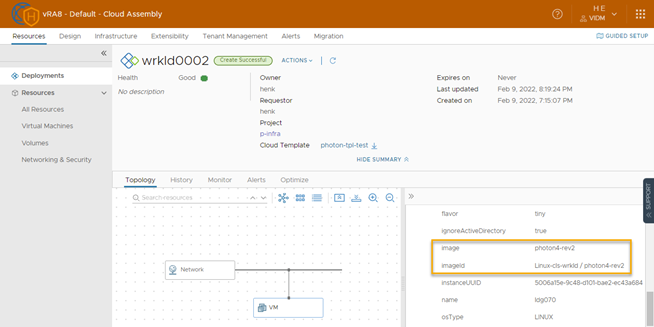
The same result is found when deploying in a cluster in another datacenter as you can see in the image below: imageId is “Linux-dc-zulu/photon4-rev2“
Besides checking the imageId after deployment, you can also tail/check the content library log from vCenter. The file you need to look at is /var/log/vmware/content-library/cls.log
See the log snippet below:
| ImportSessionActivity | Created disk transfer session urn:transfer:4f02c820-cf28-4947-98c8-3565a8b82322 for import session 15f2ae99-a4ec-45ad-b06d-8c8251a721f4 to VM vldg0200004 from library item photon4-rev2 (ID: 9d3908aa-7416-49cf-ad1d-b793037e7384) in library Linux-dc-zulu (ID: 8dea9374-4b16-4f47-a051-d8141aa705f2)How does vRA find the template to be used?
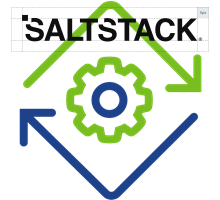
Thanks to a great session we had with Engineering, we found out the way that vRA finds the template to be used: After receiving a provisioning request with cluster, datastore and template, vRA will search for all replica templates corresponding to the publisher template. vRA then chooses the replica template based on the following sequence;
- Replica template on the target data store?
- Replica templates on the storage of target?
- If no replica template is found, the publisher template is used.
The flowchart for the above process looks as follows: